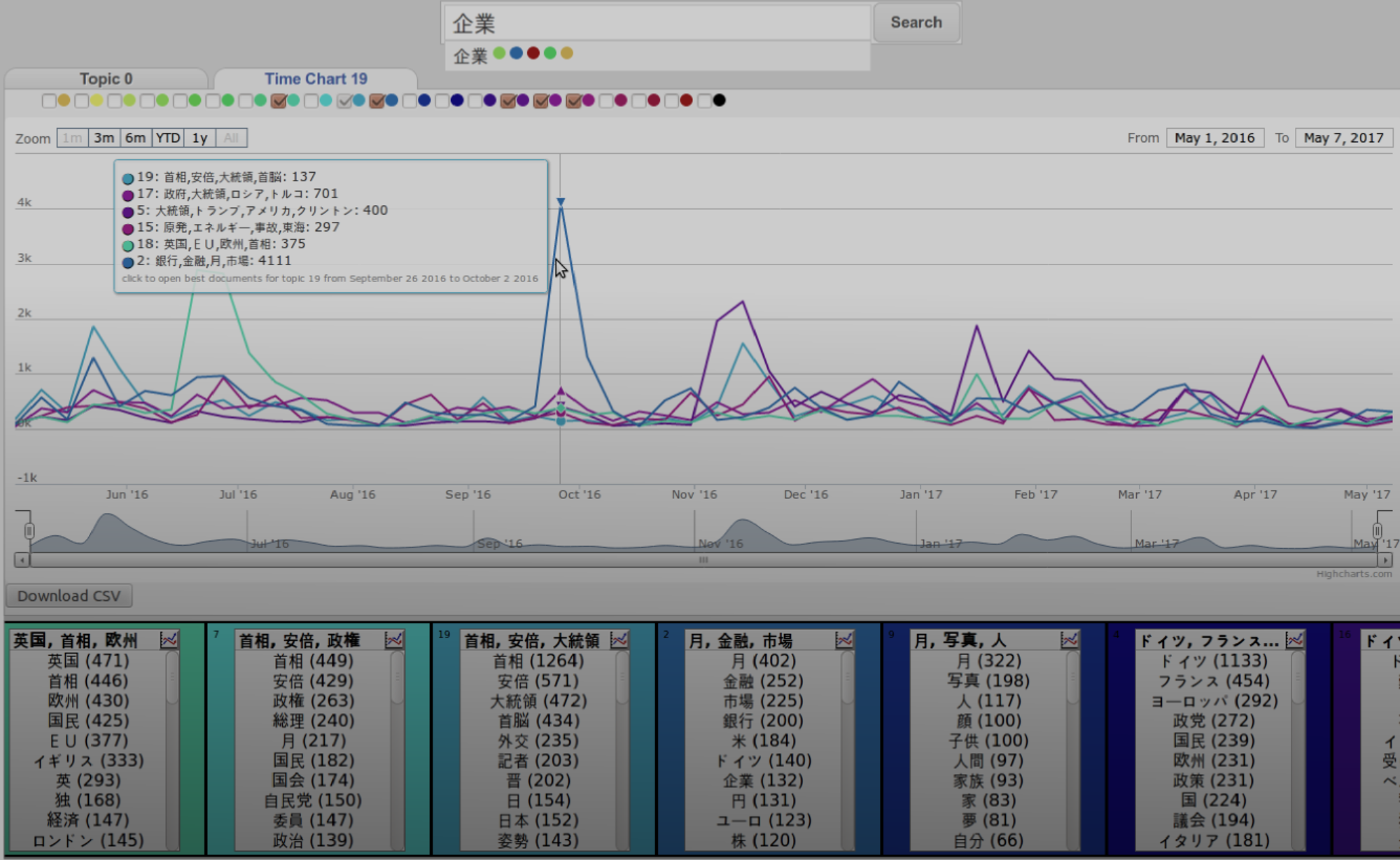
TopicExplorer is designed as middleware that connects machine learning and topic inference with databases and visual web-based user interfaces. It can be easily adapted to very different application domains through a novel workflow based plug-in-mechanism. The system stores the training data of the topic model, the inference output and additional data depending on the application. It is designed to scale to very large data. Different data stores can be mixed to give optimal performance, e.g. different types of SQL and No-SQL databases. Currently, we develop an ecosystem of micro-services around the TopicExplorer core-application. This includes services for data-import like a blog-crawler, corpus configuration and topic model tuning. The goal is to provide a functionally complete, sustainable, web-based self-service around topic modeling for non-technical end users like researchers from the humanities and social sciences.
Source-Code
The source code of TopicExplorer and most of the accompanying services is hosted on github.com under GNU Affero General Public License v3.0.
https://github.com/hinneburg/TopicExplorer
Reports about bugs and other issues, feature requests and support with programming and documentation are welcome.
The TopicExplorer software for data preprocessing and the backend of the web-application is written in Java and SQL. The web-frontend is a single-page-application written in Javascript using the model-view-viewmodel (MVVM) library knockoutjs. The web-application for the configuration of the topic-model and tuning the vocabulary for the analysis is also written in Java (backend) and Javascript/knockout (frontend). The recent web-applications for the configuration and filtering of text corpora and starting the creation of a TopicExplorer as well as the non-public blog-crawler are written in Haskell (backend) and Elm (fontend).
Natural Language Processing, Machine Learning and Databases
Documents texts are preprocessed using the part-of-speech (POS) tagging software treetagger for German and English and mecab for Japanese. The topic-model inference is done with mallet. All results from NLP-POS tagging and topic-modeling are stored in a relational databases. During preprocessing a lot of additional information is derived from those results mainly using SQL.