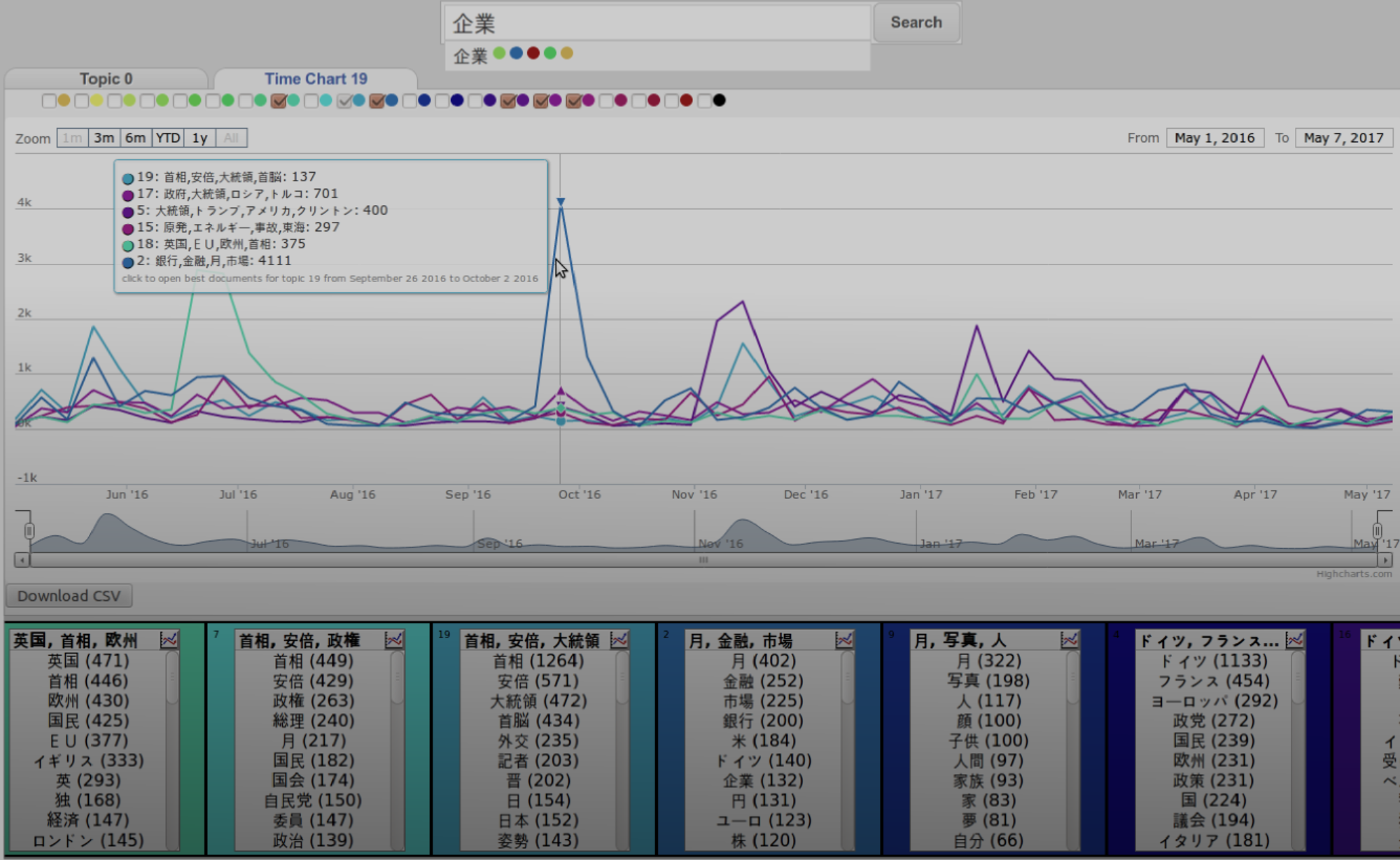
In this part, I explore the option to refactor the model of the elm-TopicExplorer-client such that identifiers for topics link out to all data relevant to viewing and interacting with topics. Starting with the topic hierarchy, this strategy leads to an overall implementation that is decomposed into several small reusable modules. This allows to easily implement different variants of the web-interface that can be tested in user studies.
The refactored appliction [demo] fully implements the hierarchy navigation. After loading the data, the inferred topics are displayed.
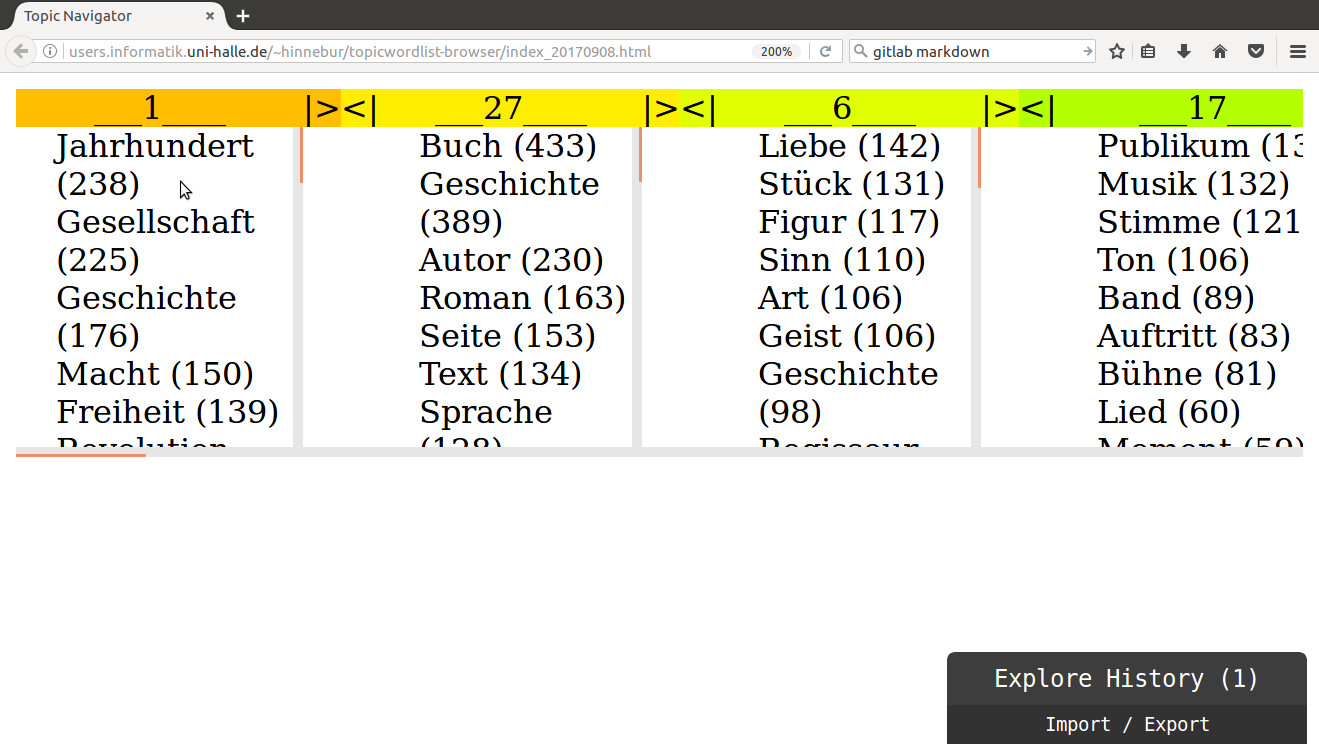
When placing the mouse between topics, a hint is shown by changing the color. It displays which topics would be merged, when the two neighboring topics are merged. Depending on the hierarchy, this may include more topics in addition to the two neighboring topics. The more topics are affected by a merge, the less similar are the two neighboring topics.
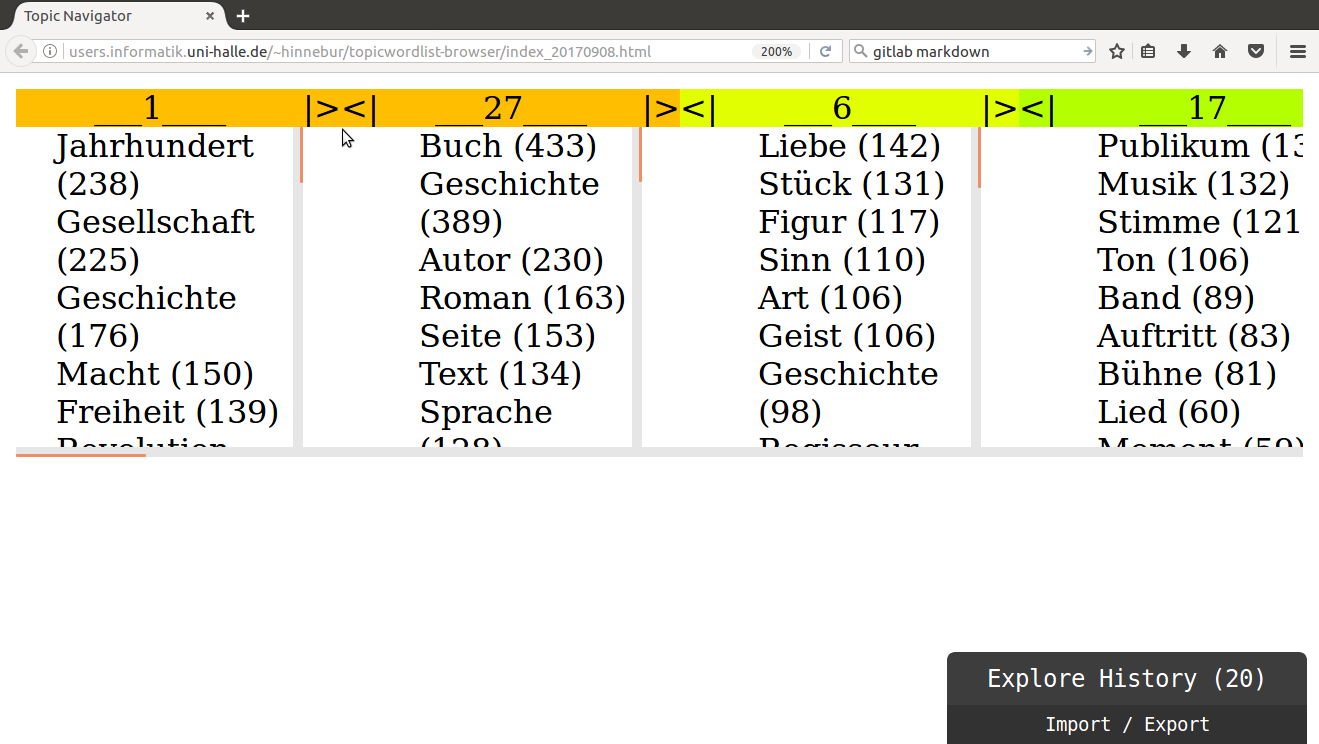
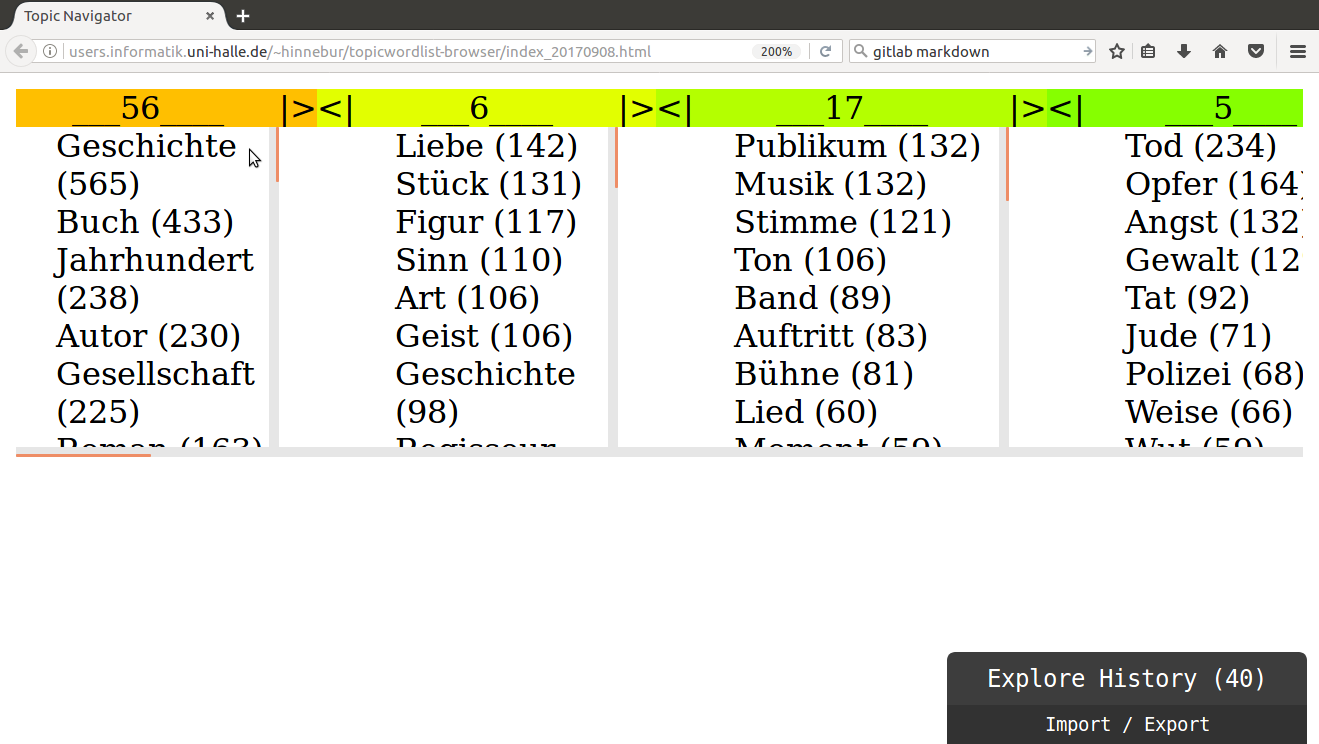
When actually merging the topics, the affected topics are replaced in the view by the topic that is the lowest common ancestor of two neighboring topics in the topic hierarchy.
The [code after refactoring] is available online. The [code] before the refactoring is also still available.
The refactoring started by removing all code pieces from the hierarchy module that are related to data necessary to view a topic. Such data included the words of a topic and the topic color. After the removal, all functions in the hierarchy module work with topic Ids (i.e. integers) only. This made not only the functions simpler, but it also reduced the number of functions needed. In the old version, there was a function to produce the data for the view of the topics when showing a hint how a merge of two neighboring topics would take effect. Then there was another function to produce the data for viewing of topics, when two topics had been merged. Furthermore, it was clear that each time some additional view data is added, the hierarchy module would have to be touched.
The new version of the hierarchy module contains just functions for navigating upwards (merging) and downwards (splitting) the topic hierarchy. The number of lines of code halved, even in the old version not all functionalities had been fully implemented. Furthermore, as long as no additional functionality related to hierarchy navigation is needed, the module will stay unchanged.
The handling of hints for topic mergers is now moved to a new module called HierarchicalTopics. In addition to that, it handles all the interactive transitions involved in hierarchy navigation: computing the hint for a topic merger, turning the hint of, merging two topics, splitting a topic. All those transitions are handled by a separate update function, which among other things just calls the functions of the hierarchy module. Thus, functionality for hierarchy navigation and the interaction model for hierarchy navigation are separated now. Now, different interaction models could be plugged in to create, test and compare alternative user interfaces.
Beside the handling of topic Ids, the application still needs to map the Ids to the relevant data to be able to actually show a topic. The result of the mapping comprises the list of words with high probability for a topic, the topic color and the topic Id itself. The mapping of a topic Id to e.g. topic color is implemented using an array. The mapping function as well as the array is part of a module that is responsible for the particular data of a topic. Thus, we have two modules ColorTopics and WordTopics for color and word lists respectively. Any additional data necessary to create a new view of a topic in the future should be placed into a separate module. Importing different combinations of such modules makes it quite flexible to create user interfaces showing different data along with a topic.
The overall model of the whole application contains pieces of every module: the hierarchy and the hint of HierarchicalTopics, the mapping arrays of ColorTopics and WordTopics as well as other data. The functions in those modules take only parts of the overall model as input. Thus it would shield the code from future extensions, if only the relevant part of the model would appear in the type signatures of the functions instead of the full type of the overall model. The concept of extensible records [1], [2], [3] allows to specify those parts as type alias. Thus, we added the respective extensible record types to the modules. Further, all other parts of the overall model is also put distributed as extensible record types to other modules. This includes the Core module and the Data module. Thus, the type of the overall model can be composed of the extensible record types of the modules used in the application. The elm compiler type checks that everything fits together.
The last consequence from working with topic Ids is that the view functions contain calls of several mapping functions to retrieve the right content data for the view. The idea of view selectors [4] helped to restructure the view functions in a readable way. Maybe the use of Html.Lazy could even improve performance of the elm application, as suggested in [5].
In the next part, I use the current implementation as a build block for an application to visually compare different topic models for the same document collection.
[1]: Elm Documentation: Record Types.
[2]: Richard Feldman: Scaling Elm Apps, Elm Europe, June, 2017.
[3]: Charlie Koster: Advanced Types in Elm – Extensible Records, 2017-09-02.
[4]: Charlie Koster: Upgrade your Elm Views with Selectors, 2016-12-19.
[5]: Charlie Koster: Upgrade your Elm Views: Part 2, 2016-12-22.