Im Normalfall möchte man mehrere Bildseiten erkennen. Für die Stapelverarbeitung ist es von Vorteil eine gewisse Infrastruktur einzurichten, damit möglichst viele Schritte automatisch abgearbeitet werden können.
Am Beginn steht eine gleichbleibende Ordnerstruktur, durch die man sich leicht bewegen kann. Manche Ordner werden von den Ocropus-Modulen selbstständig angelegt, andere kann man selbst definieren. Abbildung 1 zeigt die Ordnerstrukur, mit der ich arbeite.
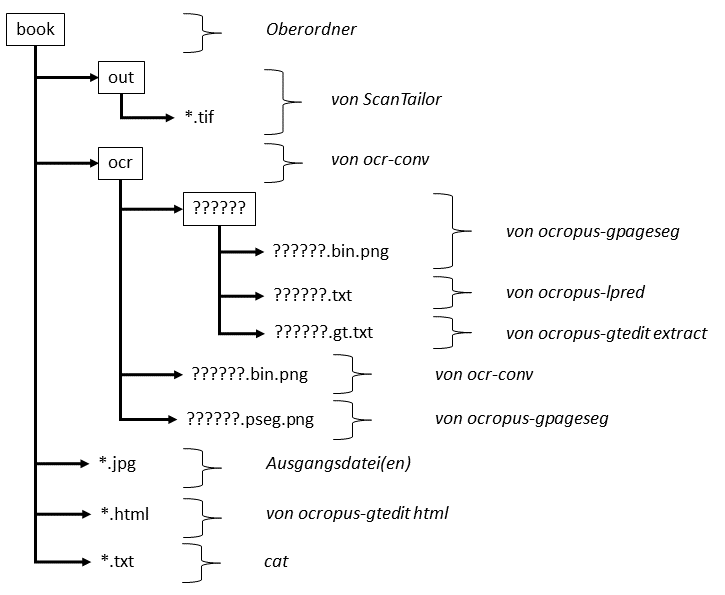
Im Hauptordner book lege ich die Ausgangsdateien ab, z.B. jpg-Dateien.
In einem vorhergehenden Artikel habe ich ScanTailor als Vorverarbeitungsprogramm beschrieben. ScanTailor gibt tif-Dateien aus, standardmäßig im Ordner out.
Diese Dateien lassen sich mit dem Programm mogrify in png-Dateien umwandeln. Ich habe das kleine Bash-Script ocr-conv geschrieben, dass
1. einen Ordner ./ocr erstellt (./ bedeutet im gleichen Verzeichnis, also book/ocr),
2. tif-Dateien, die in einem Ordner „./out“ liegen, batchartig png-Dateien umwandelt
3. diese png-Dateien in den Ordner ./ocr kopiert
4. diese png-Dateien eine sechsstellige Laufnummer gibt.
Damit es funktioniert muss man sich im Ordner book befinden, mit einem Unterordner ocr in dem die ScanTailor-tifs gespeichert sind, dann einfach
$ bash ocr-conv.bash
Ist dieser Schritt erledigt, folgt die Bildsegmentierung, Texterkennung, Korrektur und der Textexport. Erklärungen zu diesen Schritten folgen in den nächsten Artikeln. Hier geht es erst einmal hauptsächlich um eine funtkionierende Ordnerstruktur bzw. um eine Stapelverarbeitung.
Je nachdem wie viele Bilder (und Zeilen in diesen Bildern) erkannt werden sollen, erstellen die ocropus-Module entsprechend viele Ordner und Dateien. Die Fragezeichen symbolisieren hier die Laufnummern. Für die drei Dateien 0000001.png, 000002.png und 000003.png würden also immer die dazugehörigen Ordner ./0000001 , ./0000002 und ./0000001 und Verarbeitungsdateien ??????.bin.png angelegt werden.
Mit dem kleinen Script ocr-png2html.bash laufen die Segmentierung, Texterkennung und Transformation zur html automatisch durch. Auch dieses muss sich im Hauptordner book befinden. Dann starten mit:
$ bash ocr-png2html.bash
Hierbei erzeugt ocropus-gpageseg die Dateien ??????.pseg.png, die Ordner ./ocr/?????? mit den darin befindlichen Dateien ??????.bin.png
Das Texterkennungmodul ocropus-lpred die dazugehörigen ??????.txt und
ocropus-gtedit die Korrektur correction.html.
Wenn man will, kann man jetzt Fehler korrigieren. Um zu schauen, ob die Ordnerstruktur konzise ist, mache ich jedoch gleich weiter mit
$ ocorpus-gtedit extract correction.html
Damit werden die Groundtruth-Text-Dateien ??????.gt.txt in den Ordnern ./ocr/?????? erzeugt.
Mit cat erstellt man sich zum Schluss die finale *.txt-Datei.
$ cat ./ocr/??????/??????.gt.txt > ocr.txt
Wie man sieht sind die Ergebnisse noch sehr schlecht. In den folgenden Artikeln gehe ich näher darauf ein, wie man die einzelnen Module anpasst und sich eigene Erkennungsmodule trainiert, um schnellere und bessere Ergebnisse zu erzielen.
HELLO
HELLO
HAVE FUN Click!
VEGUS168 พบกับสุดยอดความบันเทิง
the best
Click!
vegus
Greats
Click!
vegus168
Do you know that you’ve done something really great? Not only did I gain new knowledge through you, but I also gained a very different realization. I’m so lucky to know your blog. 메이저사이트
An intriguing discussion may be worth comment. I’m sure you should write much more about this topic, may well be described as a taboo subject but generally folks are too little to chat on such topics. An additional. Cheers 사설토토사이트
There are some things to supplement, but I think your opinion is definitely worth considering. In some areas, innovative ideas that no one has ever come up with stand out. I would like to share more opinions with you on this topic. 먹튀사이트
This site really good
vegus168
Most people, including me, agree with you, but you shouldn’t forget that people who don’t. We need to persuade them. For a better world!
nice
Found your post interesting to read. I can’t wait to see your post soon. Good Luck for the upcoming update. This article is really very interesting and effective. 스포츠토토사이트
This type of article that enlighted me all throughout and thanks for this.This going to be excitement and have fun to read. thank to it. check this out to for further exciting. 메이저토토사이트
I wish I had someone like you next to me. Then I could have asked you a lot of advice. I’m so glad I got to know you through your post. Your writing helped me a lot. I think you and I will be able to exchange good opinions. Please visit my blog when you have time. 스포츠토토사이트
This site really good
สล็อต168
No one would agree with you more completely than I do me. It’s a really logical and elegant summary of what I want to say. I want to look around your blog more. I’m sure there are more good topics on my blog that you can write about. Please come and check. 메이저놀이터
This blog is really awesome. At first, I went around your blog lightly, but the more I read, the more gem-like articles I read. I like reading your writing. Many people are looking for topics related to your writing, so you will be of great help to them. 스포츠토토사이트
Great Blog
1688 คาสิโน
This one is what I have been looking for. 메이저 사이트 all the information is very useful for all the people who are really intersted in.
Great content
www vegus168
This site really good
vegus168 member
VEGUS168S เกี่ยวกับเรา