Benötigt wird das Programm: https://qgis.org/ Alle Dateien werden hier zwei Tage vor der Veranstaltung abrufbar sein.
Webservices und Geodatenportale schaffen heute wichtige Grundlagen für die Nachnutzung moderner räumlicher Daten. Freie Lizenzen ermöglichen einen schnellen Zugriff und eine digitale Visualisierung, weshalb räumliche Analysen in den Digital Humanities zunehmend an Bedeutung gewinnen. Projekte zur Georeferenzierung historischer Karten und zur Modellierung historischer Raumbeziehungen nehmen zu, stellen ihre Daten jedoch nicht immer offen bereit. Mit der Open-Source-Software QGIS steht seit 2002 ein leistungsfähiges Werkzeug zur eigenständigen Verarbeitung und Präsentation räumlicher Informationen zur Verfügung. Der Workshop vermittelt anhand eines Beispiels die Georeferenzierung historischer Karten, die Erstellung eigener Layer, Datenanbindung und Analyse. Abschließend werden Fragen der Dokumentation, Publikation in Forschungsdatenrepositorien sowie Qualitätskriterien und Herausforderungen bei der Nachnutzung historischer Geodaten diskutiert.
Manchmal erzählen Zahlen Geschichten. Die Zahl 2.000.000 erzählt von jahrelanger gemeinsamer Arbeit, von Forschung, Datenpflege und dem Engagement einer internationalen Community.
Mit der „Keilschrifttafel Ontario 2, 461“ wurde auf FactGrid das zweimillionste Item angelegt – ein besonders schönes Jubiläumsobjekt, denn es steht exemplarisch für das, was FactGrid ausmacht: die Verknüpfung von Forschungsdaten über Disziplinen, Projekte und Ländergrenzen hinweg. Entstanden ist dieses Jubiläums-Item im Umfeld der Projekte zur Erfassung und Erforschung altorientalischer Keilschrifttexte und Sammlungen auf FactGrid.
Seit seiner Gründung hat sich FactGrid zu einer einzigartigen, offenen Forschungsinfrastruktur entwickelt. Auf Basis von Wikibase entstehen hier Wissensnetze, in denen historische Personen, Orte, Objekte, Quellen und Forschungsdaten miteinander verbunden werden. Was mit einer ambitionierten Idee begann, ist heute eine Plattform mit Millionen von Datensätzen und einer lebendigen Community aus Forschenden, Gedächtnisinstitutionen und Ehrenamtlichen.
Das zweimillionste Item ist deshalb nicht nur ein weiterer Datensatz. Es steht stellvertretend für die vielen Menschen und Projekte, die FactGrid Tag für Tag wachsen lassen.
Herzlichen Glückwunsch an Olaf, das FactGrid-Team, an alle Projektpartnerinnen und Projektpartner sowie an die gesamte Community zu diesem großartigen Meilenstein. Auf die nächsten zwei Millionen! 🎉🥂📚
Die Normierung historischer Ortsdaten ist eine zentrale Herausforderung der digital-geisteswissenschaftlichen Forschung. Da ein (deutschlandweit) übergreifendes historisches Ortsverzeichnis fehlt, erheben Projekte diese Daten meist aufwändig selbst. Angebote wie GeoNames, Wikidata oder die GND stoßen bei historischen Zuständen (z.B. Grenzänderungen oder Wüstungen) jedoch oft an ihre Grenzen. In diesem Online-Workshop stellen wir den Lösungsansatz der AG „Minimaldatensatz Orte“ vor. Nach einem kompakten Überblick über Vor- und Nachteile gängiger digitaler Gazetteers folgt ein interaktiver Teil. Hierzu laden wir die Teilnehmenden ein, in Arbeitsgruppen Ortsangaben zu sichten und anhand der entsprechenden Vorschläge strukturiert zu erheben. Gemeinsam wollen wir die Ergebnisse diskutieren und praxisnahe Lösungen ausloten, die dann auch in unterschiedlichste Projektstrukturen integriert werden können.
Ausführliche Informationen zum Minimaldatensatz, Tipps und Anleitungen finden sich auf dem Blog der AG.
Mitwirkende der vier geisteswissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) treffen sich zum GND-Forum Humanities@NFDI am 23./24. Juni in Göttingen. Zentrales Thema des Arbeitstreffens ist die Gemeinsame Normdatei (GND) aus unterschiedlichen Blickwinkeln.
Die Gemeinsame Normdatei (GND) verbindet unterschiedliche Ressourcen, Datenbestände und Fachgemeinschaften. Vor diesem Hintergrund steht in Göttingen die Frage im Mittelpunkt, welchen Beitrag die GND – sowohl als Infrastruktur für Normdaten als auch als kooperative Organisationsstruktur – für den weiteren Ausbau der Zusammenarbeit zwischen den geisteswissenschaftlichen NFDI-Konsortien NFDI4Culture, NFDI4Memory, NFDI4Objects und Text+ leisten kann.
Anlass für diese Diskussion sind zum einen die für 2028 erwartete Neuausrichtung des NFDI-Förderprogramms, zum anderen die Frage, wie die in den Konsortien bereits entstandenen Erfahrungen, Werkzeuge und Vernetzungen im Umfeld der GND stärker konsortienübergreifend genutzt werden können.
Die Diskussion erfolgt aus drei Perspektiven:
Die Einbindung der GND in Tools und Services der Konsortien (Teil 1)
Unterschiedliche Sichtweisen auf ausgewählte Entitätstypen der GND (Teil 2)
Potenziale einer vertieften Zusammenarbeit der Konsortien auf Basis der GND (Teil 3)
Das Programm
Tag 1
11:30 Uhr: Öffnung der Registrierung vor Ort
12:30 Uhr: Begrüßung
12:45 Uhr: Teil 1: Tools und Anwendungen mit GND-Bezug in 3 Durchgängen in 6 Runden: Constrainify. DANTE. entityXML. FactGrid. Federated Content Search (FCS). GND-Dokumentation. GNDplus. GND Reconciliation Service. Registry Text+. R:honovo. RISM. TextGrid.
14:30 Uhr: Pause
15:00 Uhr: Teil 2: Entitäten-Fishbowl in 4 Gängen
Geografika
Sachbegriffe
Körperschaften
Werke
17:50 Uhr: Ausblick auf Tag 2
Tag 2
10:00 Uhr: Begrüßung
10:15 Uhr: Teil 3: Das Zukunftspotenzial der GND als Lingua Franca in der Zusammenarbeit der vier geisteswissenschaftlichen Konsortien (als Strategie Pow Wow) mit Christian Bracht (NFDI4Culture); José Calvo Tello (Text+), Jürgen Kett (GND), Katrin Moeller (NFDI4Memory), Regine Stein (NFDI) und Dirk Wintergrün (NFDI4Objects).
12:00 Uhr: Wrap up
12:30 Uhr: Veranstaltungsende
Zur Anmeldung und ausführlichen Informationen geht es hier
Wikibase konstruktiv nutzen – vom eigenen Projekt zur Kooperation; Hands-on Workshop
– für die Dateneingabe ist ein vorher initialisiertes und mit Kontaktdaten ausgestattetes Klarnamen-Konto Voraussetzung, Sie können es per mail an: olaf.simons@pierre-marteau.com anlegen lassen –
Wikibase-Instanzen zu starten, war noch nie so einfach wie heute. Dank der Angebote von Wikimedia kann inzwischen praktisch jede*r mit eigenen Daten innerhalb weniger Minuten loslegen: Eine frische, kostenlos bereitgestellte Instanz ist schnell eingerichtet und bereit, Wissen strukturiert zu erfassen und miteinander zu vernetzen.
Doch das ist nur eine von mehreren Möglichkeiten. Wer seine Daten lieber in ein bestehendes, global vernetztes System einbringen möchte, kann sie direkt in Wikidata integrieren. Für historische Datenbestände wiederum bietet sich FactGrid an, das gezielt für solche Anwendungsfälle entwickelt und gefördert wurde.
Alle drei Wege haben ihren eigenen Reiz – und ihre ganz spezifischen Herausforderungen. Eine eigene Wikibase-Instanz bietet maximale Freiheit: Strukturen lassen sich individuell gestalten, ohne Abstimmungsprozesse oder externe Vorgaben. In großen, kollaborativen Umgebungen hingegen ist Koordination unverzichtbar. Dafür eröffnen sich dort ganz andere Möglichkeiten der Modellierung und Vernetzung.
Unabhängig vom gewählten Ansatz gilt: Mit Wikibase lassen sich Dinge umsetzen, die in dieser Form mit klassischer Datenbanksoftware kaum oder nur sehr aufwendig realisierbar wären.
Dieser Kurs bietet einen praxisnahen Einstieg in die Welt von Wikibase. Er zeigt die wichtigsten Optionen, beleuchtet typische Herausforderungen und lädt dazu ein, selbst erste Schritte zu wagen.
Der Workshop richtet sich insbesondere an Studierende und Forschende, die mit (historischen) Datenbeständen arbeiten und sich für Themen wie Wikibase, FactGrid, Knowledge Graphen oder NFDI4Memory interessieren.
Das GOV-Erfassungsprojekt „Gemeindelexika Preußen 1885“ läuft seit Juli 2024 und hat zum Ziel, die Ortsdaten der 13 Gemeindelexika 1885 für Preußen komplett zu erfassen. GOV ist die Abkürzung für das „Geschichtliche Ortsverzeichnis” des Vereins für Computergenealogie (CompGen). Die maximale Projektlaufzeit dafür reicht bis zum Februar 2028; je nach Geschwindigkeit und technischer Entwicklung kann es auch schneller gehen. Die Ersterfassung der Gemeindeebene ist bis Ende 2026 geplant. Im Anschluss daran müssen diese noch überarbeitet und bei Bedarf noch die Wohnplatzebene ergänzt werden. Das Projekt wird in Kooperation mit dem Verein für Computergenealogie mit der Task-Area 2 „Data Connecitivity“ von NFDI4Memory durchgeführt. Verantwortlicher Projektleiter ist Julian Freytag. Realisiert wird das Projekt durch den Einsatz mehrerer Hilfskräfte in der Datenerfassung.
Warum ist das wichtig?
Die Gemeindelexika bieten standardisierte Angaben zu Städten, Landgemeinden, Gutsbezirken und den jeweils zugehörigen Amtsbezirken, Standesamtsbezirken sowie evangelischen und katholischen Kirchspielen – und enthalten darüber hinaus umfangreiche Zahlenangaben zu Wohnplätzen, Gebäuden, Haushalten und Bevölkerungszahlen nach Geschlecht, Religion und Militärstatus.
Für genealogische wie historische Fragestellungen eröffnen sie damit eine gute Möglichkeit, Orts- und Verwaltungsdaten klar strukturiert und systematisch zu erfassen. Qualitativ hochwertige und möglichst genaue Ortsdaten, die die exakte Identifizierung eines Ortes etwa in genealogischen oder historischen Quellen ermöglichen, sind für die Forschung sehr wichtig. Der geografische Fokus der Erfassung liegt zunächst auf Preußen, da hier alle Gemeindelexika einheitlich veröffentlicht wurden. Zudem sind gerade in den östlicheren Provinzen noch größere Lücken im GOV vorhanden. Zeitlich wurde das Jahr der Volkszählung 1885 ausgewählt, weil auch hier noch größere Lücken vorlagen und damit das GOV zu diesem einen Zeitpunkt in Hinblick auf Preußen flächendeckend erfasst ist. Die über das DES erfassten Daten werden zur besseren Vernetzung in das GOV integriert, wodurch zahlreiche Verknüpfungen und Hierarchien hergestellt und die Datenqualität wesentlich verbessert wird.
Wie läuft das Projekt konkret ab?
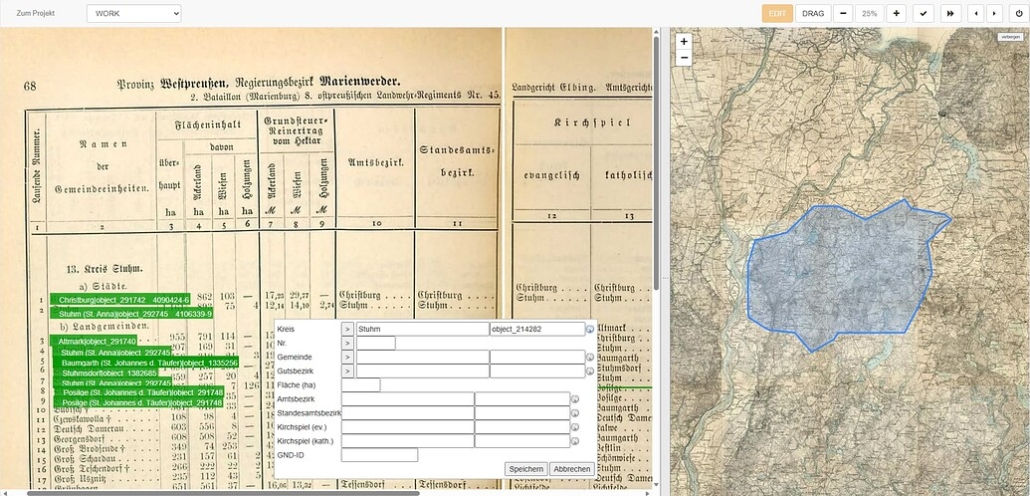
Beispiel der Erfassung von Verwaltungsobjekten mit dem DatenEingabeSytem DES
Die Erfassung erfolgt bandweise, d.h. Provinz für Provinz – insgesamt 13 Bände stammen aus den Jahren 1887/88. Im Hauptteil des Projekts werden im DatenEingabeSytem DES die Verwaltungsobjekte wie Städte, Landgemeinden und Gutsbezirke mit den zugehörigen Amtsbezirken, Standesamtsbezirken und Kirchspielen erfasst. Anschließend wird der Zahlenapparat für jede Einheit aufgenommen: Wohnplätze, Gebäude, Haushalte, Gesamtbevölkerung, männlich/weiblich, aktive Militärpersonen, evangelische, katholische, sonstige Christen, Juden, andere Religionsbekenntnisse.
Parallel ist die Erfassung der Wohnplatzebene in Erprobung: Jeder Wohnplatz und jedes Gut soll mit Punktkoordinate, Gebäude- und Einwohnerzahl sowie mit Zugehörigkeit zum darüber liegenden Verwaltungsobjekt erfasst werden. Diese Erfassungstiefe ist bei vielen Ortsdatenbanken in dieser Breite noch Neuland. Derzeit ist der Band „Pommern“ für die Wohnplätze in Erprobung.
Nach Abschluss eines Bandes wird der Datensatz nach entsprechender Qualitätskontrolle ins GOV eingespielt. Etwaige Fehler und Ungenauigkeiten werden dabei erneut korrigiert.
Worin liegt der Mehrwert?
Es werden quantitativ und qualitativ hochwertige und miteinander verknüpfte Ortsdaten für einen konkreten historischen Zeitpunkt erfasst, die die komplette Verwaltungshierarchie abdecken.
Das Projekt schafft eine flächendeckende, einheitliche Erfassung der Ortsdaten im GOV für die preußischen Provinzen für den Zeitpunkt 1885. Zahlreiche Lücken bei vielen Objekttypen werden geschlossen. Damit ist eine gute Vergleichsgrundlage für etwaige spätere Erfassungen gegeben, um etwa statistische Angaben im zeitlichen Verlauf zu analysieren.
Mit der Wohnplatzebene rückt die kleinteilige Erfassung historischer Siedlungsobjekte in den Fokus. Hier sind im GOV noch größere Lücken vorhanden, die somit geschlossen werden. Die bereits erfassten Wohnplätze werden hingegen den zugehörigen Verwaltungseinheiten zugeordnet (Städte, Gemeinden, Gutsbezirke).
Vorhandene Probleme im GOV werden gelöst: Hierbei ist neben dem Ausmachen von Dubletten u.a. die „Lösung“ des Problems der „Stewner-Gemeinden“ vor allem in Pommern und Posen zu nennen. Diese zuvor massenweise umgewandelten Landgemeinden wurden wiederhergestellt und den Wohnplätzen übergeordnet. Außerdem konnten etwa in Ostpreußen zahlreiche vermischte Objekttypen klar getrennt werden.
Wie ist der derzeitige Stand und wo liegen aktuelle Probleme?
Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)
Bis April 2026 haben wir Folgendes erreicht: Auf der ersten Ebene der Verwaltungsebene sind die Bände Pommern, Posen, Ostpreußen, Westpreußen, Brandenburg und Sachsen abgeschlossen. Mit insgesamt gut 32.000 Daten sind das bereits 58% des Gesamtumfangs. Pommern und Posen sind schon größtenteils ins GOV eingespielt; die Einspielung der weiteren Provinzen hängt von der finalen Überarbeitung ab. Die Erfassung der Wohnplätze befindet sich noch in der Probephase. Hier wird derzeit der Band Pommern bearbeitet. Nach erfolgreicher Erprobung ist dann bei Bereitstellung der entsprechenden Mittel auch die Erfassung weiterer Provinzen geplant.
Bei der bisherigen Erfassung konnten bereits zahlreiche Probleme im GOV gelöst werden, wie etwa Dubletten, falsch zugeordnete Objekttypen oder das Schließen etwaiger Lücken. Mit jeder neuen Provinz ergeben sich neue Herausforderungen, die einerseits mit den historischen Gegebenheiten der Verwaltung in der jeweiligen Provinz zusammenhängen und andererseits mit dem Abbilden derselben im GOV. In der Provinz Sachsen etwa sind zahlreiche Wohnplätze und Gemeinden vermischt, die erst aufwendig getrennt werden müssen. In den Provinzen Ost- und Westpreußen sind die Besonderheiten der Städtestruktur zu beachten. Für alle Provinzen müssen die fehlenden Kirchspiele in anderen Quellen recherchiert werden, da die Kirchenhierarchie im GOV anders abgebildet wird als in den Gemeindelexika.
Ausblick
Für 2026 ist der Abschluss der Gemeindeebene geplant. Die Erfassung der Wohnplätze wird je nach Zeitaufwand parallel fortgesetzt, die Priorität liegt aber zunächst auf der Gemeindeebene. Der Workflow für die Erfassung ist nun etabliert und die Hilfskräfte sind eingearbeitet, daher wird die weitere Erfassung schneller vorangehen. Etwaige Verzögerungen entstehen in der Regel eher durch größere Mengen problematischer und nicht einheitlicher Daten im GOV, denn durch die eigentliche Erfassung.
Die Projektleitung freut sich auf Fragen und Anmerkungen, die unter dieser Mailadresse an uns geschickt werden können. Die Projektdokumentation findet sich hier im GenWiki.
Mitwirkende der vier geisteswissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) treffen sich zum GND-Forum Humanities@NFDI am 23./24. Juni in Göttingen. Zentrales Thema des Arbeitstreffens ist die Gemeinsame Normdatei (GND) aus unterschiedlichen Blickwinkeln.
Die Veranstalter:innen
Das GND-Forum Humanities@NFDI wird organisiert von: Barbara Fischer (Deutsche Nationalbibliothek, GND-Community), Stefan Buddenbohm & Alex Steckel (SUB Göttingen als Gastgeberin sowie Text+). Melanie Gruss & Desiree Mayer (NFDI4Culture), Anja Gerber & Frank von Hagel (NFDI4Objects), Katrin Moeller und Anne Purschwitz (NFDI4Memory), Domenic Schäfer & Michael Markert (VZG des GBV).
GND-Forum Humanities@NFDI
Im Kontext der NFDI versteht sich die Gemeinsame Normdatei (GND) als zentrale Infrastruktur, die unterschiedliche Datenressourcen, Fachcommunities und Forschungspraktiken miteinander verbindet. Vor diesem Hintergrund stellt sich die Frage, wie ihre doppelte Rolle als Datenbasis und organisatorischer Rahmen zur Weiterentwicklung der Zusammenarbeit zwischen den geisteswissenschaftlichen Konsortien NFDI4Culture, NFDI4Memory, NFDI4Objects und Text+ beitragen kann. Diese Fragestellung steht im Mittelpunkt des Austauschs in Göttingen.
Ausgangspunkt der Diskussion sind sowohl die für 2028 erwartete strategische Weiterentwicklung des NFDI-Förderrahmens als auch die Frage, wie bestehende Synergien und Entwicklungen rund um die GND innerhalb der einzelnen Konsortien konsortienübergreifend nutzbar gemacht werden können.
Die Diskussion erfolgt entlang von drei Perspektiven:
die Rolle der GND in Tools und Services der NFDI-Konsortien
unterschiedliche fachliche Perspektiven auf ausgewählte Entitätstypen innerhalb der GND
Zukunftsperspektiven einer vertieften, GND-basierten Zusammenarbeit zwischen den geisteswissenschaftlichen Konsortien
Themen
Im Sinne einer aktiven Beteiligung der Community soll allen Teilnehmenden die Möglichkeit geben, sich in die Diskussion einzubringen. Dafür ist ein programmatischer Dreiklang vorgesehen, der die Rolle der GND im Kontext der NFDI aus unterschiedlichen Perspektiven beleuchtet:
Tools: Welche Werkzeuge für welche Zwecke? Im Mittelpunkt steht die Frage, wie GND-basierte Daten, Dienste und Schnittstellen in den geisteswissenschaftlichen NFDI-Konsortien eingesetzt werden und welche Anforderungen sich daraus für zukünftige Entwicklungen ergeben.
Die GND im Schulterblick: Entitätentypen in der Anwendung In Tandems aus GND- und NFDI-Kolleg:innen werden ausgewählte Entitätentypen der GND praxisnah vorgestellt und in ihren jeweiligen Anwendungskontexten innerhalb der NFDI-Konsortien verortet.
Strategie: Entwicklungspfade der GND in der NFDI Abschließend werden Perspektiven für die Weiterentwicklung der GND als zentrale Infrastruktur innerhalb der NFDI diskutiert – mit Blick auf nachhaltige Kooperationen, Interoperabilität und gemeinsame strategische Zielsetzungen.
Anmeldung
Bitte meldet Euch bis zum 16.06. über die Anmeldefunktion dieser Veranstaltungsseite an. Es stehen 80 Plätze für Teilnehmende zur Verfügung. Die Teilnahme am GND-Forum ist kostenfrei.
…forschende Institutionen oder Projekte: universitätseigene oder außeruniversitäre Forschungseinrichtungen sowie Citizen Science Projekte
…Einzelpersonen mit eigenen Projekten: Young Career (Master- und Dissertationsprojekte)
Service
Beratung zu Projekten in allen Projektphasen:
erste Orientierungsberatung zu Zielen oder Machbarkeit des eigenen Projektes
problemfokussierte Beratung im laufenden Projekt
Beratung zur (finalen) Datenpublikation und Anbindung an andere Datenbanken vor oder nach Abschluss des Projektes
Hilfestellung zu Schwerpunktsetzung(en) + (finanziellen und personellen) Spielräumen des eigenen Projekts im Bezug auf Verwendung/Erstellung/Sammlung/Verwaltung usw. von historischen Ortsdaten
Beratung zur Machbarkeit/praktischen Umsetzbarkeit der angestrebten Ziele
Einführung in die Nachnutzung/Verknüpfung und Recherche in allgemein vorhandene kontrollierte Vokabulare und Datenquellen zu historischen Ortsdaten
Wann, wo und wie beraten wir?
Wann: immer am ersten Mittwoch des Monats, 13:00 Uhr
Wo: Online (Link wird zugeschickt)
Voraussetzungen:
spätestens eine Woche vorher: Voranmeldung
spätestens drei Tage vorher: Zusendung einer kleinen Problemskizze
Dauer: eine Sitzung etwa 60-90 Minuten
Folgeberatungen nach individueller Absprache
Was machen wir nicht?
Antragsberatung oder Letters of Intent
Forschungsdatenmanagement (allgemein)
langfristige Betreuung von Projekten
Einführung in GIS-Anwendungen, Beratung zur Umsetzung von Visualisierungen oder Geolokalisierung von und auf historischem Kartenmaterial
Am 16. März 2026 fand das sechste GND-Forum Archiv unter dem Motto „Mitmachen!“ online statt. Im Mittelpunkt stand die Frage, wie sich Archive aktiv in die Gemeinsame Normdatei (GND) einbringen können.
Ein besonderer Höhepunkt war das offene Publikumsgespräch unter dem Titel „Wir sind eine GND-Agentur! – Anforderungen und Erfahrungen“. Auf dem Podium diskutierten Patrick Leiske (GND-Agentur LEO BW Regional, im Dauerbetrieb), Gudrun Hoinkis (GND-Agentur Staatsarchiv, im Pilotbetrieb) sowie Anne Purschwitz (GND-Agentur Geschichtswissenschaften, in Gründung im Rahmen von NFDI4Memory). Die Moderation übernahm Mirjam Sprau.






 Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)
Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)

 Bild: J. Kett (DNB) CC BY SA
Bild: J. Kett (DNB) CC BY SA