Die Zeit eilt dahin. Die Halbzeit der ersten Förderphase von NFDI4Memory ist verstrichen und so wurde vor kurzem auch der Zwischenbericht eingereicht.
Projektbeschreibung
27. Apr. 2026
GOV-Erfassungsprojekt-Gemeindelexika „Data4GOV“ – Zwischenstand Frühjahr 2026
Das GOV-Erfassungsprojekt „Gemeindelexika Preußen 1885“ läuft seit Juli 2024 und hat zum Ziel, die Ortsdaten der 13 Gemeindelexika 1885 für Preußen komplett zu erfassen. GOV ist die Abkürzung für das „Geschichtliche Ortsverzeichnis” des Vereins für Computergenealogie (CompGen). Die maximale Projektlaufzeit dafür reicht bis zum Februar 2028; je nach Geschwindigkeit und technischer Entwicklung kann es auch schneller gehen. Die Ersterfassung der Gemeindeebene ist bis Ende 2026 geplant. Im Anschluss daran müssen diese noch überarbeitet und bei Bedarf noch die Wohnplatzebene ergänzt werden. Das Projekt wird in Kooperation mit dem Verein für Computergenealogie mit der Task-Area 2 „Data Connecitivity“ von NFDI4Memory durchgeführt. Verantwortlicher Projektleiter ist Julian Freytag. Realisiert wird das Projekt durch den Einsatz mehrerer Hilfskräfte in der Datenerfassung.
Warum ist das wichtig?
Die Gemeindelexika bieten standardisierte Angaben zu Städten, Landgemeinden, Gutsbezirken und den jeweils zugehörigen Amtsbezirken, Standesamtsbezirken sowie evangelischen und katholischen Kirchspielen – und enthalten darüber hinaus umfangreiche Zahlenangaben zu Wohnplätzen, Gebäuden, Haushalten und Bevölkerungszahlen nach Geschlecht, Religion und Militärstatus.
Für genealogische wie historische Fragestellungen eröffnen sie damit eine gute Möglichkeit, Orts- und Verwaltungsdaten klar strukturiert und systematisch zu erfassen. Qualitativ hochwertige und möglichst genaue Ortsdaten, die die exakte Identifizierung eines Ortes etwa in genealogischen oder historischen Quellen ermöglichen, sind für die Forschung sehr wichtig. Der geografische Fokus der Erfassung liegt zunächst auf Preußen, da hier alle Gemeindelexika einheitlich veröffentlicht wurden. Zudem sind gerade in den östlicheren Provinzen noch größere Lücken im GOV vorhanden. Zeitlich wurde das Jahr der Volkszählung 1885 ausgewählt, weil auch hier noch größere Lücken vorlagen und damit das GOV zu diesem einen Zeitpunkt in Hinblick auf Preußen flächendeckend erfasst ist. Die über das DES erfassten Daten werden zur besseren Vernetzung in das GOV integriert, wodurch zahlreiche Verknüpfungen und Hierarchien hergestellt und die Datenqualität wesentlich verbessert wird.
Wie läuft das Projekt konkret ab?
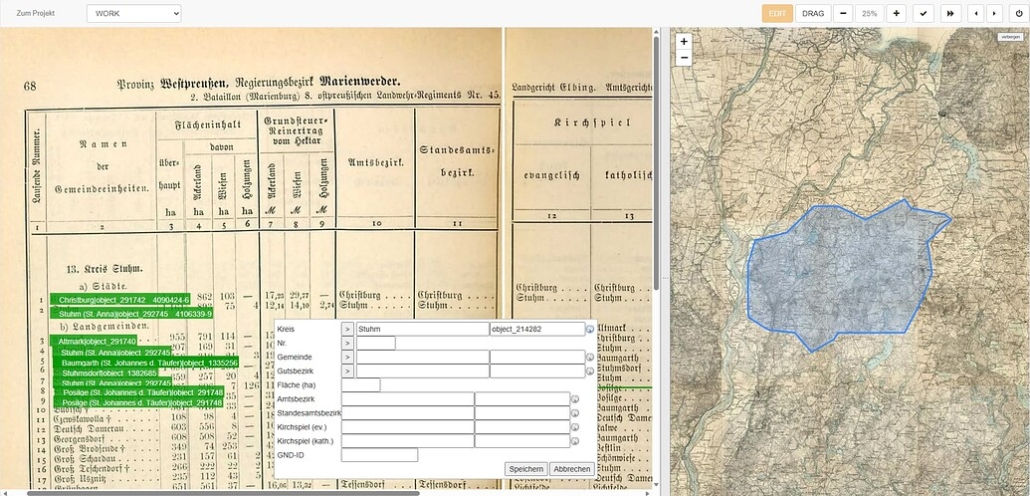
Die Erfassung erfolgt bandweise, d.h. Provinz für Provinz – insgesamt 13 Bände stammen aus den Jahren 1887/88. Im Hauptteil des Projekts werden im DatenEingabeSytem DES die Verwaltungsobjekte wie Städte, Landgemeinden und Gutsbezirke mit den zugehörigen Amtsbezirken, Standesamtsbezirken und Kirchspielen erfasst. Anschließend wird der Zahlenapparat für jede Einheit aufgenommen: Wohnplätze, Gebäude, Haushalte, Gesamtbevölkerung, männlich/weiblich, aktive Militärpersonen, evangelische, katholische, sonstige Christen, Juden, andere Religionsbekenntnisse.
Parallel ist die Erfassung der Wohnplatzebene in Erprobung: Jeder Wohnplatz und jedes Gut soll mit Punktkoordinate, Gebäude- und Einwohnerzahl sowie mit Zugehörigkeit zum darüber liegenden Verwaltungsobjekt erfasst werden. Diese Erfassungstiefe ist bei vielen Ortsdatenbanken in dieser Breite noch Neuland. Derzeit ist der Band „Pommern“ für die Wohnplätze in Erprobung.
Nach Abschluss eines Bandes wird der Datensatz nach entsprechender Qualitätskontrolle ins GOV eingespielt. Etwaige Fehler und Ungenauigkeiten werden dabei erneut korrigiert.
Worin liegt der Mehrwert?
- Es werden quantitativ und qualitativ hochwertige und miteinander verknüpfte Ortsdaten für einen konkreten historischen Zeitpunkt erfasst, die die komplette Verwaltungshierarchie abdecken.
- Das Projekt schafft eine flächendeckende, einheitliche Erfassung der Ortsdaten im GOV für die preußischen Provinzen für den Zeitpunkt 1885. Zahlreiche Lücken bei vielen Objekttypen werden geschlossen. Damit ist eine gute Vergleichsgrundlage für etwaige spätere Erfassungen gegeben, um etwa statistische Angaben im zeitlichen Verlauf zu analysieren.
- Mit der Wohnplatzebene rückt die kleinteilige Erfassung historischer Siedlungsobjekte in den Fokus. Hier sind im GOV noch größere Lücken vorhanden, die somit geschlossen werden. Die bereits erfassten Wohnplätze werden hingegen den zugehörigen Verwaltungseinheiten zugeordnet (Städte, Gemeinden, Gutsbezirke).
- Vorhandene Probleme im GOV werden gelöst: Hierbei ist neben dem Ausmachen von Dubletten u.a. die „Lösung“ des Problems der „Stewner-Gemeinden“ vor allem in Pommern und Posen zu nennen. Diese zuvor massenweise umgewandelten Landgemeinden wurden wiederhergestellt und den Wohnplätzen übergeordnet. Außerdem konnten etwa in Ostpreußen zahlreiche vermischte Objekttypen klar getrennt werden.
Wie ist der derzeitige Stand und wo liegen aktuelle Probleme?
 Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)
Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)
Bis April 2026 haben wir Folgendes erreicht: Auf der ersten Ebene der Verwaltungsebene sind die Bände Pommern, Posen, Ostpreußen, Westpreußen, Brandenburg und Sachsen abgeschlossen. Mit insgesamt gut 32.000 Daten sind das bereits 58% des Gesamtumfangs. Pommern und Posen sind schon größtenteils ins GOV eingespielt; die Einspielung der weiteren Provinzen hängt von der finalen Überarbeitung ab. Die Erfassung der Wohnplätze befindet sich noch in der Probephase. Hier wird derzeit der Band Pommern bearbeitet. Nach erfolgreicher Erprobung ist dann bei Bereitstellung der entsprechenden Mittel auch die Erfassung weiterer Provinzen geplant.
Bei der bisherigen Erfassung konnten bereits zahlreiche Probleme im GOV gelöst werden, wie etwa Dubletten, falsch zugeordnete Objekttypen oder das Schließen etwaiger Lücken. Mit jeder neuen Provinz ergeben sich neue Herausforderungen, die einerseits mit den historischen Gegebenheiten der Verwaltung in der jeweiligen Provinz zusammenhängen und andererseits mit dem Abbilden derselben im GOV. In der Provinz Sachsen etwa sind zahlreiche Wohnplätze und Gemeinden vermischt, die erst aufwendig getrennt werden müssen. In den Provinzen Ost- und Westpreußen sind die Besonderheiten der Städtestruktur zu beachten. Für alle Provinzen müssen die fehlenden Kirchspiele in anderen Quellen recherchiert werden, da die Kirchenhierarchie im GOV anders abgebildet wird als in den Gemeindelexika.
Ausblick
Für 2026 ist der Abschluss der Gemeindeebene geplant. Die Erfassung der Wohnplätze wird je nach Zeitaufwand parallel fortgesetzt, die Priorität liegt aber zunächst auf der Gemeindeebene. Der Workflow für die Erfassung ist nun etabliert und die Hilfskräfte sind eingearbeitet, daher wird die weitere Erfassung schneller vorangehen. Etwaige Verzögerungen entstehen in der Regel eher durch größere Mengen problematischer und nicht einheitlicher Daten im GOV, denn durch die eigentliche Erfassung.
Die Projektleitung freut sich auf Fragen und Anmerkungen, die unter dieser Mailadresse an uns geschickt werden können. Die Projektdokumentation findet sich hier im GenWiki.
24. März 2026
Das historische Vornamentool ist veröffentlicht!
Unsere Arbeitsgruppe hat ein neues Service-Tool zur Arbeit mit Personendaten veröffentlicht!
Mit dem historischen Vornamentool – kurz hivoto – kann Vornamen jeweils ein wahrscheinliches Geschlecht sowie eine Normbezeichnung zugewiesen werden.
hivoto wurde im Vorfeld der DHd in Wien online publiziert und im Rahmen der Tagung mit einem Vortrag präsentiert und steht ab sofort in Radar4Memory zur Verfügung. Der Datensatz kann hier zusammen mit einer Dokumentation als CSV- und SAV-Datei heruntergeladen werden.
Darüber hinaus werden Normschreibungen sowie Schreib- und Sprachvarianten in FactGrid eingespeist und stehen dort zur weiteren Nutzung und Vernetzung zur Verfügung.
10. Nov. 2025
Die TA2 auf der FORGE Rostock
Vom 24. bis zum 26. September 2025 trafen sich in Rostock Akteur:innen aus Wissenschaft, Dateninfrastruktur und Forschung, die sich mit geisteswissenschaftlichen Forschungsdaten beschäftigen. Im Zentrum des Tagungsmottos stand die Frage, wie Forschungsdaten in den Geisteswissenschaften anders gedacht und genutzt werden können: also Daten neu denken?

Präsentationen und Workshops auf der FORGE
Die ‚AG Historische Ortsdaten‘ an der sich die TA2 des Historischen Datenzentrums intensiv beteiligt war auf der FORGE mit einem gut besuchten und sehr anregenden halbtägigen Workshop zum Umgang mit historischen Ortsdaten vertreten. Das Format brachte Interessierte aus unterschiedlichen Fachrichtungen zusammen und zeigte deutlich, wie vielfältig die Herangehensweisen an historische Ortsdaten derzeit noch sind – zugleich aber auch, auf welchen Gemeinsamkeiten künftig eine stärker strukturierte Zusammenarbeit aufbauen kann.
Ein zentraler Bezugspunkt war die Empfehlung zum Minimaldatensatz Ortsdaten, die eine hervorragende Grundlage für weiterführende Abstimmungen und Projekte bietet.

Ergebnisse des Workshops Historische Ortsdaten auf der FORGE in Rostock: Bild: Anne Purschwitz.
Kontrollierte Vokabulare und Normdaten
Am zweiten Tagungstag konnte sich die TA2 mit zwei Beiträge zu aktuellen Entwicklungen im Umgang mit kontrollierten Vokabularen und Normdaten vorstellen. Beide Vorträge verdeutlichten, dass Vokabulare in der digitalisierten Forschungslandschaft – etwa im Kontext von Künstlicher Intelligenz, Natural Language Processing oder der Datenkuratierung – eine zentrale Rolle spielen.
Vorgestellt wurde von Katja Liebing und Marius Wegener das Register R:hovono, das einen Überblick über für die historisch arbeitenden Wissenschaften relevante Vokabulare bietet und verstreute Informationen zusammenführt. Es schafft damit eine Grundlage für die bessere Auffindbarkeit und Nachnutzbarkeit von Vokabularen im Sinne der FAIR-Prinzipien. Über die Wikibase-Instanz FactGrid (Vortrag von Katrin Moeller und Anne Purschwitz) können Forschende Vokabulare selbstständig eintragen, abfragen und miteinander vernetzen.
Der zweite Beitrag verdeutlichte am Beispiel der „Ontologie der historischen, deutschsprachigen Amts- und Berufsbezeichnungen (OhdAB)“, wie sich kontrollierte Vokabulare konkret in vernetzte Forschungsdateninfrastrukturen integrieren lassen. Dabei wurden sowohl die Potenziale als auch die Herausforderungen im Umgang mit Linked Open Data diskutiert. Beide Vorträge machten deutlich, dass kontrollierte Vokabulare nicht nur technisches Hilfsmittel, sondern ein zentrales Bindeglied für Kooperation, Nachnutzung und Qualitätssicherung in den historisch arbeitenden Disziplinen sind.
Die FORGE in Rostock bot nicht nur herrliches Wetter und eine tolle Atmosphäre, sondern überzeugte auch durch hochkarätige Teilnehmende, intensive Gespräche und Diskussionen – besonders die Vernetzung der geisteswissenschaftlichen NFDI-Konsortien gelang auf angenehme Weise.
Getragen und organisiert
wurde die FORGE von der Arbeitsgruppe Geisteswissenschaftliches Forschungsdatenmanagement (AG gwFDM) des Verbands Digital Humanities in deutschsprachigen Raum (DHd), der Juniorprofessur für Digital Humanities, der Universitätsbibliothek Rostock, dem Department “Wissen – Kultur – Transformation” (WKT) der Interdisziplinären Fakultät der Universität Rostock und dem Rostocker Arbeitskreis Digital Humanities (RosDH).
13. Feb. 2024
Ortsdatenprojekte in der NFDI4Memory-TA2
Derzeit beschäftigen wir uns mit zwei konkreten Ortsdatenprojekten im Rahmen unserer Arbeit für mehr data connectivity.
[ Weiterlesen … ]27. Nov. 2023
Start der Erfassung für unser Register historischer Normdaten und Vokabulare
Nachdem wir die vorläufige Version des Erfassungsbogens erfolgreich auf dem NFDI4Memory-Community-Treffen vorgestellt haben, können wir nun endlich mit der eigentlichen Erfassung beginnen. Die Eingabemaske läuft über das Programm LimeSurvey der Martin-Luther-Universität Halle-Wittenberg.
[ Weiterlesen … ]23. Okt. 2023
Blog Projektzugehörigkeit
Alle Aktivitäten, Informationen und Angebote dieses Blogs gehen auf die Arbeiten der Task Area 2 „NFDI4Memory“-Arbeitsgruppe am Historischen Datenzentrum Sachsen-Anhalt im Rahmen des NFDI-Konsortiums 4Memory zurück (www.4memory.de). Wir danken der Deutschen Forschungsgemeinschaft (DFG) für die finanzielle Unterstützung – Projektnummer 501609550.
20. Okt. 2023
TASK AREA 2 „Data Connectivity“
TA2 „Data Connectivity“ arbeitet mit zwei Arbeitsgruppen in München und Halle (Saale) an der Verknüpfung und Kontextualisierung von geschichtswissenschaftlichen Forschungsdaten, um ein zeitgemäßes Datenmanagement zu ermöglichen und das Fundament für den geplanten 4Memory-Data-Space zu bilden. Sie soll den Grundstein für historisch sensible und eindeutige Norm- und Metadaten legen, forschungsbasierte historische Kategorisierungen herausarbeiten und für die gemeinsame Nutzung für das Semantic Web mit denen von Archiven, Bibliotheken und Museen verknüpfen, um so größere Datenstrukturen und -mengen zu kontextualisieren. Datenkonnektivität ist für die Erreichung der LINKAGE-Ziele von entscheidender Bedeutung.
[ Weiterlesen … ]20. Okt. 2023
NFDI4Memory
Bei NFDI4Memory handelt es sich um das Konsortium für geschichtswissenschaftlich arbeitende Disziplinen, das neben den Konsortien NFDI4Culture, NFDI4Objects und Text+ zu den vier geisteswissenschaftlichen Konsortien gehört. Bei NFDI4Memory arbeiten Forschungseinrichtungen sowie Gedächtnisinstitutionen (Archive, Bibliotheken, Sammlungen, Museen) eng zusammen. Ein Schwerpunkt sind Methoden der digitalen Quellenkritik und die Kontextualisierung von Daten. Die Arbeit des 4Memory-Konsortiums ist in sechs „Task Areas“ organisiert, die – in wechselseitiger Zusammenarbeit – jeweils unterschiedliche Aspekte zur Verbesserung des Forschungsdatenmanagements in den historisch orientierten Geisteswissenschaften behandeln, neue Standards für historische Daten und für eine digitale historische Quellenkritik setzen und die 4Memory-Community im digitalen Raum begleiten und ausbauen.
20. Okt. 2023
Was sind die Nationalen Forschungsdateninfrastrukturen?
Die Nationale Forschungsdateninfrastruktur (NFDI) ermöglichen eine systematische Erschließung, Vernetzung sowie nachhaltige und qualitativ hochwertige Nutzbarkeit von Forschungsdaten für das deutsche Wissenschaftssystem und gestalten damit die Transformation der Wissenschaften in das digitale Zeitalter. Während bisher Daten meist dezentral, projektbezogen oder zeitlich begrenzt zugänglich waren, soll mithilfe von NFDI Wissen dauerhaft digital gespeichert werden und nach den FAIR-Prinzipien (Findable, Accessible, Interoperable, Reusable) verfügbar gemacht werden. Dies ermöglicht neue Wege und Strategien der Erkenntnisbildung und damit neue Innovationen.
Die NFDI teilt sich auf in 27 Konsortien, in denen sich unterschiedliche Institutionen eines Forschungs- und Fachbereichs zusammenschließen, um diese Ziele zu erreichen.