Wikibase konstruktiv nutzen – vom eigenen Projekt zur Kooperation; Hands-on Workshop
– für die Dateneingabe ist ein vorher initialisiertes und mit Kontaktdaten ausgestattetes Klarnamen-Konto Voraussetzung, Sie können es per mail an: olaf.simons@pierre-marteau.com anlegen lassen –
Wikibase-Instanzen zu starten, war noch nie so einfach wie heute. Dank der Angebote von Wikimedia kann inzwischen praktisch jede*r mit eigenen Daten innerhalb weniger Minuten loslegen: Eine frische, kostenlos bereitgestellte Instanz ist schnell eingerichtet und bereit, Wissen strukturiert zu erfassen und miteinander zu vernetzen.
Doch das ist nur eine von mehreren Möglichkeiten. Wer seine Daten lieber in ein bestehendes, global vernetztes System einbringen möchte, kann sie direkt in Wikidata integrieren. Für historische Datenbestände wiederum bietet sich FactGrid an, das gezielt für solche Anwendungsfälle entwickelt und gefördert wurde.
Alle drei Wege haben ihren eigenen Reiz – und ihre ganz spezifischen Herausforderungen. Eine eigene Wikibase-Instanz bietet maximale Freiheit: Strukturen lassen sich individuell gestalten, ohne Abstimmungsprozesse oder externe Vorgaben. In großen, kollaborativen Umgebungen hingegen ist Koordination unverzichtbar. Dafür eröffnen sich dort ganz andere Möglichkeiten der Modellierung und Vernetzung.
Unabhängig vom gewählten Ansatz gilt: Mit Wikibase lassen sich Dinge umsetzen, die in dieser Form mit klassischer Datenbanksoftware kaum oder nur sehr aufwendig realisierbar wären.
Dieser Kurs bietet einen praxisnahen Einstieg in die Welt von Wikibase. Er zeigt die wichtigsten Optionen, beleuchtet typische Herausforderungen und lädt dazu ein, selbst erste Schritte zu wagen.
Der Workshop richtet sich insbesondere an Studierende und Forschende, die mit (historischen) Datenbeständen arbeiten und sich für Themen wie Wikibase, FactGrid, Knowledge Graphen oder NFDI4Memory interessieren.
Das GOV-Erfassungsprojekt „Gemeindelexika Preußen 1885“ läuft seit Juli 2024 und hat zum Ziel, die Ortsdaten der 13 Gemeindelexika 1885 für Preußen komplett zu erfassen. GOV ist die Abkürzung für das „Geschichtliche Ortsverzeichnis” des Vereins für Computergenealogie (CompGen). Die maximale Projektlaufzeit dafür reicht bis zum Februar 2028; je nach Geschwindigkeit und technischer Entwicklung kann es auch schneller gehen. Die Ersterfassung der Gemeindeebene ist bis Ende 2026 geplant. Im Anschluss daran müssen diese noch überarbeitet und bei Bedarf noch die Wohnplatzebene ergänzt werden. Das Projekt wird in Kooperation mit dem Verein für Computergenealogie mit der Task-Area 2 „Data Connecitivity“ von NFDI4Memory durchgeführt. Verantwortlicher Projektleiter ist Julian Freytag. Realisiert wird das Projekt durch den Einsatz mehrerer Hilfskräfte in der Datenerfassung.
Warum ist das wichtig?
Die Gemeindelexika bieten standardisierte Angaben zu Städten, Landgemeinden, Gutsbezirken und den jeweils zugehörigen Amtsbezirken, Standesamtsbezirken sowie evangelischen und katholischen Kirchspielen – und enthalten darüber hinaus umfangreiche Zahlenangaben zu Wohnplätzen, Gebäuden, Haushalten und Bevölkerungszahlen nach Geschlecht, Religion und Militärstatus.
Für genealogische wie historische Fragestellungen eröffnen sie damit eine gute Möglichkeit, Orts- und Verwaltungsdaten klar strukturiert und systematisch zu erfassen. Qualitativ hochwertige und möglichst genaue Ortsdaten, die die exakte Identifizierung eines Ortes etwa in genealogischen oder historischen Quellen ermöglichen, sind für die Forschung sehr wichtig. Der geografische Fokus der Erfassung liegt zunächst auf Preußen, da hier alle Gemeindelexika einheitlich veröffentlicht wurden. Zudem sind gerade in den östlicheren Provinzen noch größere Lücken im GOV vorhanden. Zeitlich wurde das Jahr der Volkszählung 1885 ausgewählt, weil auch hier noch größere Lücken vorlagen und damit das GOV zu diesem einen Zeitpunkt in Hinblick auf Preußen flächendeckend erfasst ist. Die über das DES erfassten Daten werden zur besseren Vernetzung in das GOV integriert, wodurch zahlreiche Verknüpfungen und Hierarchien hergestellt und die Datenqualität wesentlich verbessert wird.
Wie läuft das Projekt konkret ab?
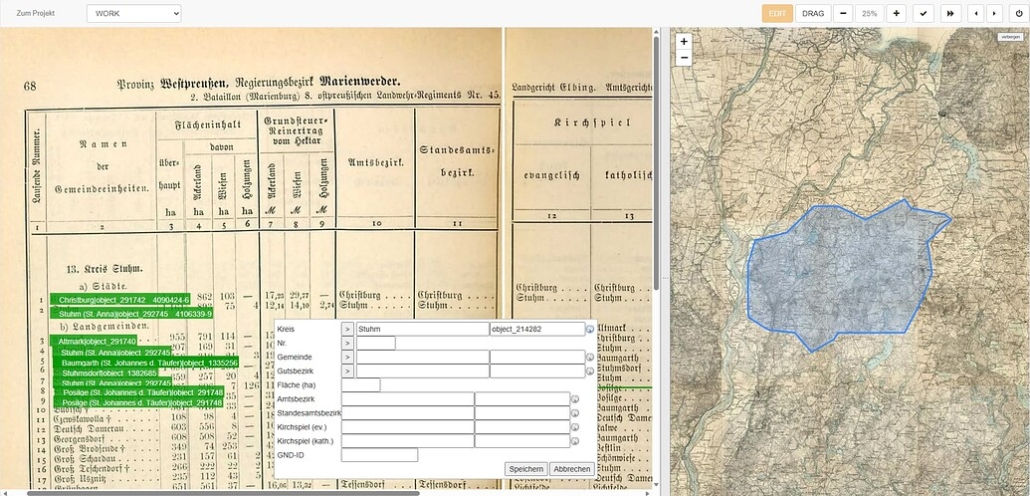
Beispiel der Erfassung von Verwaltungsobjekten mit dem DatenEingabeSytem DES
Die Erfassung erfolgt bandweise, d.h. Provinz für Provinz – insgesamt 13 Bände stammen aus den Jahren 1887/88. Im Hauptteil des Projekts werden im DatenEingabeSytem DES die Verwaltungsobjekte wie Städte, Landgemeinden und Gutsbezirke mit den zugehörigen Amtsbezirken, Standesamtsbezirken und Kirchspielen erfasst. Anschließend wird der Zahlenapparat für jede Einheit aufgenommen: Wohnplätze, Gebäude, Haushalte, Gesamtbevölkerung, männlich/weiblich, aktive Militärpersonen, evangelische, katholische, sonstige Christen, Juden, andere Religionsbekenntnisse.
Parallel ist die Erfassung der Wohnplatzebene in Erprobung: Jeder Wohnplatz und jedes Gut soll mit Punktkoordinate, Gebäude- und Einwohnerzahl sowie mit Zugehörigkeit zum darüber liegenden Verwaltungsobjekt erfasst werden. Diese Erfassungstiefe ist bei vielen Ortsdatenbanken in dieser Breite noch Neuland. Derzeit ist der Band „Pommern“ für die Wohnplätze in Erprobung.
Nach Abschluss eines Bandes wird der Datensatz nach entsprechender Qualitätskontrolle ins GOV eingespielt. Etwaige Fehler und Ungenauigkeiten werden dabei erneut korrigiert.
Worin liegt der Mehrwert?
Es werden quantitativ und qualitativ hochwertige und miteinander verknüpfte Ortsdaten für einen konkreten historischen Zeitpunkt erfasst, die die komplette Verwaltungshierarchie abdecken.
Das Projekt schafft eine flächendeckende, einheitliche Erfassung der Ortsdaten im GOV für die preußischen Provinzen für den Zeitpunkt 1885. Zahlreiche Lücken bei vielen Objekttypen werden geschlossen. Damit ist eine gute Vergleichsgrundlage für etwaige spätere Erfassungen gegeben, um etwa statistische Angaben im zeitlichen Verlauf zu analysieren.
Mit der Wohnplatzebene rückt die kleinteilige Erfassung historischer Siedlungsobjekte in den Fokus. Hier sind im GOV noch größere Lücken vorhanden, die somit geschlossen werden. Die bereits erfassten Wohnplätze werden hingegen den zugehörigen Verwaltungseinheiten zugeordnet (Städte, Gemeinden, Gutsbezirke).
Vorhandene Probleme im GOV werden gelöst: Hierbei ist neben dem Ausmachen von Dubletten u.a. die „Lösung“ des Problems der „Stewner-Gemeinden“ vor allem in Pommern und Posen zu nennen. Diese zuvor massenweise umgewandelten Landgemeinden wurden wiederhergestellt und den Wohnplätzen übergeordnet. Außerdem konnten etwa in Ostpreußen zahlreiche vermischte Objekttypen klar getrennt werden.
Wie ist der derzeitige Stand und wo liegen aktuelle Probleme?
Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)
Bis April 2026 haben wir Folgendes erreicht: Auf der ersten Ebene der Verwaltungsebene sind die Bände Pommern, Posen, Ostpreußen, Westpreußen, Brandenburg und Sachsen abgeschlossen. Mit insgesamt gut 32.000 Daten sind das bereits 58% des Gesamtumfangs. Pommern und Posen sind schon größtenteils ins GOV eingespielt; die Einspielung der weiteren Provinzen hängt von der finalen Überarbeitung ab. Die Erfassung der Wohnplätze befindet sich noch in der Probephase. Hier wird derzeit der Band Pommern bearbeitet. Nach erfolgreicher Erprobung ist dann bei Bereitstellung der entsprechenden Mittel auch die Erfassung weiterer Provinzen geplant.
Bei der bisherigen Erfassung konnten bereits zahlreiche Probleme im GOV gelöst werden, wie etwa Dubletten, falsch zugeordnete Objekttypen oder das Schließen etwaiger Lücken. Mit jeder neuen Provinz ergeben sich neue Herausforderungen, die einerseits mit den historischen Gegebenheiten der Verwaltung in der jeweiligen Provinz zusammenhängen und andererseits mit dem Abbilden derselben im GOV. In der Provinz Sachsen etwa sind zahlreiche Wohnplätze und Gemeinden vermischt, die erst aufwendig getrennt werden müssen. In den Provinzen Ost- und Westpreußen sind die Besonderheiten der Städtestruktur zu beachten. Für alle Provinzen müssen die fehlenden Kirchspiele in anderen Quellen recherchiert werden, da die Kirchenhierarchie im GOV anders abgebildet wird als in den Gemeindelexika.
Ausblick
Für 2026 ist der Abschluss der Gemeindeebene geplant. Die Erfassung der Wohnplätze wird je nach Zeitaufwand parallel fortgesetzt, die Priorität liegt aber zunächst auf der Gemeindeebene. Der Workflow für die Erfassung ist nun etabliert und die Hilfskräfte sind eingearbeitet, daher wird die weitere Erfassung schneller vorangehen. Etwaige Verzögerungen entstehen in der Regel eher durch größere Mengen problematischer und nicht einheitlicher Daten im GOV, denn durch die eigentliche Erfassung.
Die Projektleitung freut sich auf Fragen und Anmerkungen, die unter dieser Mailadresse an uns geschickt werden können. Die Projektdokumentation findet sich hier im GenWiki.
Mitwirkende der vier geisteswissenschaftlichen Konsortien der Nationalen Forschungsdateninfrastruktur (NFDI) treffen sich zum GND-Forum Humanities@NFDI am 23./24. Juni in Göttingen. Zentrales Thema des Arbeitstreffens ist die Gemeinsame Normdatei (GND) aus unterschiedlichen Blickwinkeln.
Die Veranstalter:innen
Das GND-Forum Humanities@NFDI wird organisiert von: Barbara Fischer (Deutsche Nationalbibliothek, GND-Community), Stefan Buddenbohm & Alex Steckel (SUB Göttingen als Gastgeberin sowie Text+). Melanie Gruss & Desiree Mayer (NFDI4Culture), Anja Gerber & Frank von Hagel (NFDI4Objects), Katrin Moeller und Anne Purschwitz (NFDI4Memory), Domenic Schäfer & Michael Markert (VZG des GBV).
GND-Forum Humanities@NFDI
Im Kontext der NFDI versteht sich die Gemeinsame Normdatei (GND) als zentrale Infrastruktur, die unterschiedliche Datenressourcen, Fachcommunities und Forschungspraktiken miteinander verbindet. Vor diesem Hintergrund stellt sich die Frage, wie ihre doppelte Rolle als Datenbasis und organisatorischer Rahmen zur Weiterentwicklung der Zusammenarbeit zwischen den geisteswissenschaftlichen Konsortien NFDI4Culture, NFDI4Memory, NFDI4Objects und Text+ beitragen kann. Diese Fragestellung steht im Mittelpunkt des Austauschs in Göttingen.
Ausgangspunkt der Diskussion sind sowohl die für 2028 erwartete strategische Weiterentwicklung des NFDI-Förderrahmens als auch die Frage, wie bestehende Synergien und Entwicklungen rund um die GND innerhalb der einzelnen Konsortien konsortienübergreifend nutzbar gemacht werden können.
Die Diskussion erfolgt entlang von drei Perspektiven:
die Rolle der GND in Tools und Services der NFDI-Konsortien
unterschiedliche fachliche Perspektiven auf ausgewählte Entitätstypen innerhalb der GND
Zukunftsperspektiven einer vertieften, GND-basierten Zusammenarbeit zwischen den geisteswissenschaftlichen Konsortien
Themen
Im Sinne einer aktiven Beteiligung der Community soll allen Teilnehmenden die Möglichkeit geben, sich in die Diskussion einzubringen. Dafür ist ein programmatischer Dreiklang vorgesehen, der die Rolle der GND im Kontext der NFDI aus unterschiedlichen Perspektiven beleuchtet:
Tools: Welche Werkzeuge für welche Zwecke? Im Mittelpunkt steht die Frage, wie GND-basierte Daten, Dienste und Schnittstellen in den geisteswissenschaftlichen NFDI-Konsortien eingesetzt werden und welche Anforderungen sich daraus für zukünftige Entwicklungen ergeben.
Die GND im Schulterblick: Entitätentypen in der Anwendung In Tandems aus GND- und NFDI-Kolleg:innen werden ausgewählte Entitätentypen der GND praxisnah vorgestellt und in ihren jeweiligen Anwendungskontexten innerhalb der NFDI-Konsortien verortet.
Strategie: Entwicklungspfade der GND in der NFDI Abschließend werden Perspektiven für die Weiterentwicklung der GND als zentrale Infrastruktur innerhalb der NFDI diskutiert – mit Blick auf nachhaltige Kooperationen, Interoperabilität und gemeinsame strategische Zielsetzungen.
Anmeldung
Bitte meldet Euch bis zum 16.06. über die Anmeldefunktion dieser Veranstaltungsseite an. Es stehen 80 Plätze für Teilnehmende zur Verfügung. Die Teilnahme am GND-Forum ist kostenfrei.
Am 16. März 2026 fand das sechste GND-Forum Archiv unter dem Motto „Mitmachen!“ online statt. Im Mittelpunkt stand die Frage, wie sich Archive aktiv in die Gemeinsame Normdatei (GND) einbringen können.
Ein besonderer Höhepunkt war das offene Publikumsgespräch unter dem Titel „Wir sind eine GND-Agentur! – Anforderungen und Erfahrungen“. Auf dem Podium diskutierten Patrick Leiske (GND-Agentur LEO BW Regional, im Dauerbetrieb), Gudrun Hoinkis (GND-Agentur Staatsarchiv, im Pilotbetrieb) sowie Anne Purschwitz (GND-Agentur Geschichtswissenschaften, in Gründung im Rahmen von NFDI4Memory). Die Moderation übernahm Mirjam Sprau.
Inzwischen haben wir mehr als 9.000 Lager mit unterschiedlichen Datensätzen verknüpft und sie in ihrer Widersprüchlichkeit erfasst.Gleichzeitig haben wir versucht, sie zweifelsfrei zu identifizieren. Neben mehreren Vorstellungen auf Fachtagungen eröffnet unser aktueller Beitrag die neue Thematic Series „Data on Nazi Persecution“ auf dem Document Blog des European Holocaust Research Infrastructure (EHRI) Projekt.
Am 16.09. fand im Vorfeld des Historikertags in Bonn das NFDI4Memory Community Forum statt. Hier ergab sich für Co-Applicants, Participants und interessierte Besucher:innen die Möglichkeit, sich über aktuelle Arbeitsstände und Projekte der Community zu informieren und miteinander ins Gespräch zu kommen. [ Weiterlesen … ]
Empfehlen Sie kontrollierte Vokabulare für vielfältige Nutzungsperspektiven in den historisch arbeitenden Disziplinen in einem Guide! Kontrollierte Vokabulare erfüllen heute zentrale Aufgaben bei der Verwendung von Large Language Models, der Anreicherung und Analyse von Massendaten und für die Visualisierung von Quellen. Dennoch sind Anwendungsfelder und Ressourcen für dieses wichtige Arbeitsgebiet der historischen Forschung häufig unbekannt. Wir möchten daher ein Empfehlungssystem für Vokabulare, aber auch Standards im Umgang mit bestimmten Quellen- oder Dateitypen aufbauen. [ Weiterlesen … ]
Der hiermit vorgelegte Datensatz zur deutschen Parteiengeschichte dürfte – mit aktuell 840 gelisteten Parteien – im Moment der umfassendste seiner Art im Internet sein: Frei nutzbar, in beliebiger Konfiguration herunter zu laden, in Hintergrunddaten ausgreifend und zudem (mit einem frei erhältlichen FactGrid-Konto) unter beliebigen Forschungsinteressen auf die eigenen Bedürfnisse hin bearbeitbar. [ Weiterlesen … ]
Unsere umfangreichen und vielfältigen Bemühungen haben sich gelohnt. Nach einem intensiven Januar konnte die „AG Historische Ortsdaten“ auf der DHd in Bielefeld in einem Workshop erstmals ihre Minimaldatensatz-Empfehlung präsentieren und einem Praxistest unterziehen.
Einführung und Vorstellung der Arbeitsgruppe
Nach einer allgemeinen Vorstellung der Arbeitsgruppe und der historischen Ortsdaten zugrundeliegenden Problematiken, folgte eine Einführung in den entwickelten Minimaldatensatz, der in Kurzform auf unserer Website verfügbar ist. Dieser ist stets nach dem gleichen Schema aufgebaut und bietet damit eine wertvolle Orientierungshilfe für den Umgang mit historischen Ortsdaten, nicht nur für die Teilnehmer:innen des Workshops. [ Weiterlesen … ]
Das neue Jahr hat gerade erst begonnen, aber die ersten Höhepunkte stehen schon in den Startlöchern. Dazu zählt für unsere TA2 Gruppe am Historischen Datenzentrum Sachsen-Anhalt der Launch der R:hovono Website (Register historischer und objektbezogener Vokabulare und Normdaten), auf der Ende des ersten Quartals 2025 für die historische Forschung relevante Vokabulare in einer Tiefenerschließung präsentiert werden.
Im April 2024 gestartet haben mittlerweile fast 100 historische und objektbezogene Vokabulare und Normdaten den Weg zu uns gefunden.
Wer seine Register und Vokabulare beim ersten Launch dabei haben möchte, hat noch bis zum 31. Januar 2025 die Möglichkeit eine Erfassung via LimeSurvey oder direkt im FactGrid vorzunehmen. Die Registerpräsentation unseres Workshops vom 23.04. (https://zenodo.org/records/11073414), sowie das Codebuch (https://zenodo.org/records/11031743) und die Dokumentation (https://zenodo.org/records/11033367) des Registers sind auf Zenodo veröffentlicht. Auch auf Individuelle Anfragen gehen wir gerne ein.

 Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)
Erfassung der Gemeindelexika nach Provinzen (linker Balken: Verwaltungsobjekte, rechter Balken:Wohnplätze)

 Bild: J. Kett (DNB) CC BY SA
Bild: J. Kett (DNB) CC BY SA